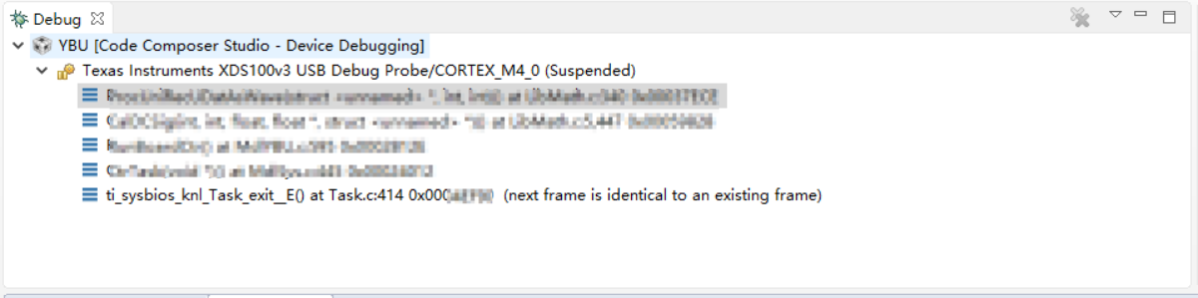
仅限常见故障,不含逻辑方面的问题
常见程度只是粗略估计,并不严谨。常见程度是我所在公司的项目经验,其他环境下可能有所差异。常见程度最大5颗⭐
1. 基础知识
1.1. 异常类型介绍
1.1.1. HardFault
HardFault大概率执行了非法的CPU指令导致的,例如:CPU不能识别的指令(烧录的程序有问题)、尝试读写非法地址的指令、尝试写入只读地址的指令(例如:常量区、代码区等)等。程序中可设置HardFault的钩子函数,出现HardFault时通常会记录崩溃现场并打印到控制台后主动重启。
1.1.2. Abort
Abort的问题通常是软件逻辑层次的问题,也就是比HardFault更偏向软件,大部分问题都是系统检查出的一些问题(例如:栈被溢出、关中断后sleep、中断服务函数中强行开软中断等),或者自定义的一些问题(例如:配置表id重复、配置表格式错误等)。默认的Abort是一个死循环,程序中可设置Abort的钩子函数,和HardFault一样也会记录崩溃现场并打印到控制台后主动重启。
1.1.3. Raise
Raise相当于系统的日志,例如:Abort和HardFault前可能会打印一些异常消息、malloc分配失败会打印异常消息,这些消息有助于排查问题。并且Raise消息不一定是error,有可能只是warning而已,也就是出现了Raise消息并不一定会崩溃。Raise的消息内容也都记录在崩溃现场中了。
1.2. 程序地址映射与备份
程序中的全局变量地址、函数地址(函数实际也可以想象成“常量区”的全局变量)每次编译的地址并不是固定的。如果程序出现问题后,知道崩溃现场,但是需要当时的程序才能解析出崩溃现场中的函数地址和变量地址。如果重新编译过,函数和变量的地址很可能发生变化,那么就没法通过崩溃现场找到对应的内容,也就没法排查问题。所以说切记调试时出现问题第一时间先备份程序,给现场升级私有版本时候也要备份好程序,防止程序不小心重新编译。注意:备份程序最少备份map文件和out文件,有条件的话尽量将整个项目(包含源码)一起备份。
1.3. 现场配置备份
如果是现场出现问题,最好也要****备份配置,防止配置修改后复现不出来,同时也方便使用现场配置在本地尝试复现。
1.4. map文件的作用
map文件里包含所有函数、变量的地址映射,通过崩溃现场得到崩溃地址的情况下可以直接通过map文件计算出是哪个函数发生崩溃。
2. 各种问题
2.1. 内存溢出问题**(常见程度⭐⭐⭐⭐⭐)**
2.1.1. 有崩溃的内存溢出,直接确定崩溃位置
- 如果栈溢出或者溢出内容到栈,TIRTOS(我公司使用的RTOS)通常能够检查出来,当TIRTOS检查出栈被溢出时先会调用Raise打印溢出信息然后再调用Abort,在Raise溢出信息中就有被溢出的内存地址、被溢出的任务地址等。
- 如果有崩溃只是能找到被溢出的位置,但是不一定导致溢出的位置,毕竟有可能溢出到其它任务的变量中,间接导致这个任务崩了。
2.1.2. 没有崩溃的内存溢出,或者没法直接确定溢出位置
- 通过map文件查看排查周围变量有哪些,通常大概率都是周围的数组变量溢出导致的。
- 通过二分法移动变量位置来确定是出现内存溢出位置,操作的时候尽量不要大改,否则有可能导致整个内存重新编址,这样就有可能不复现问题了。
- 内存值对比,对比周围内存是否与溢出变量相同的值。可以将内存导出后直接Ctrl+F搜索,说不定就能找到溢出的地方。
- 溢出不一定是连续的,因为如果是结构体的数组,并且只修改每个结构体变量的几个值,也就出现跳着间隔溢出的情况。
- 通常溢出为0的概率比较大,所以溢出内存附近如果有值是0,那么也不能排除0就是被溢出的值而非正常值。
2.1.3. 常见的溢出的情况
- 数组下标取值范围没限定好,例如:数值越界后当做下标溢出、遍历范围写了常量后期又缩小了数组等。(常见程度⭐⭐⭐⭐⭐)
- strcpy的源字符串没有结束标志,实际建议使用strncpy。(常见程度⭐⭐⭐⭐)
- strncpy、memcpy等函数传入的长度有问题。(常见程度⭐⭐⭐)
- 编译时的结构体与实际使用的结构体没有对应上,出现两个相同名称不同内容的结构体。(常见程度⭐)
2.2. 非法地址解引用**(常见程度⭐⭐⭐⭐)**
2.2.1. 问题特征与定位
通常这种问题都会直接触发HardFault,通过回溯**崩溃现场**方法就能定位位置。
2.2.2. 常见非法地址解引用的情况
- 只读地址解引用赋值,大多数情况是0地址被解引用后赋值,也就是一些地址为空的情况没判断好,例如:调用socket()没判断返回失败、非任务函数中获取使用信号量(剖析源码:导致获取任务指针失败,也就使用空指针触发信号量崩溃)、自己的指针变量一些情况等。(常见程度⭐⭐⭐⭐⭐)
- 越界地址解引用(读写一个非法地址),例如:遍历数组下标数值溢出、遍历字符串没有限定最大值并且没有字符串结束符等。(常见程度⭐⭐⭐)
- 非对齐地址解引用,例如:内存复用时,一块内存既当做uint8的值又当做uint64的值,但是没有4字节对齐,那么转成uint64就会崩溃。(常见程度⭐)
非对齐地址解引用原理实际是非法的CPU指令,CPU的地址总线大部分都是和地址是对齐的,例如:在大部分的32位CPU中,读取4字节对齐的内存可以一次性读出来,但是将非4字节对齐的内存读为32变量时,只能将这块内存分成两次来切分后拼接实现读写,如果将非4字节地址读取为64变量就不能两次切分能完成,大部分的CPU也就不支持了,所以就会出现崩溃。(TODO待考证:1,CPU完成切分操作,还是编译器完成切分操作;2,如果是CPU完成的切分操作,那么一条汇编指令还是在一个时钟周期内完成的吗)
2.3. 资源清理**(常见程度⭐⭐⭐⭐⭐)**
2.3.1. 常见的资源清理类问题
- 关中断忘记开中断。导致系统无法运行,大多数会导致看门狗重启。(常见程度⭐⭐⭐)
- pend信号量没有post信号量。比较隐蔽,信号量会少触发或者不再触发。(常见程度⭐⭐)
- 打开文件没有关闭文件。因为文件系统需要保证持久化硬件的磨损均衡,所以调用完写文件函数后有概率实际文件内容还保留在内存中,关闭文件时才同步到文件中。(常见程度⭐⭐⭐⭐)
- 创建socket没有关闭socket。通过源码能发现,socket创建时候会使用堆空间和NDK(一种示例网络协议驱动层)的静态内存,如果长期创建socket没有关闭socket会导致堆空间不足、NDK静态内存不足等。如果只是NDK静态内存不足,也就间接导致其它socket创建失败,例如:MQTT、ModbusTCP创建socket失败也就连不上了。如果是堆空间不足,那么会导致malloc分配不出内存,例如:动态创建任务失败等。这种问题会很隐蔽,很多长期运行才会复现问题,并且出现问题后有可能MQTT就已经连不上了,设备不易察觉(可考虑添加持久化日志功能,以便在通信中断时仍能记录异常信息)。(常见程度⭐⭐⭐⭐)
2.3.2. 避免方法
- 简单的资源清理建议使用if...else...进行判断,所有清理都在统一层次,如果太多太绕建议使用下面的方法。
- 复杂的资源清理可以使用do...while(0)进行判断,也就是清理的代码写在do...while(0)外,功能的代码写在do...while(0)内,失败的情况也就直接在do...while(0)内break。
- 注意:根据编码规范,不可使用goto指令,因其容易破坏代码结构,不利于维护。
2.4. 临界资源**(常见程度⭐⭐⭐⭐)**
64位、结构体、数组在32位的CPU上没办法原生支持原子操作,只能自己手动开关中断,或者是使用信号量保护,否则会出现一半变量赋值,另一半变量还是老值。
2.5. 数值越界**(常见程度⭐⭐)**
- 有符号和无符号比较,默认使用有符号指令比较,导致最高位为1的无符号数变成负数进行比较,例如:
(uint8)255 < (int8)1,这里的(uint8)255也就是当成(int8)-1进行比较。 - int8与uint32的比较,int8强制转成uint32进行比较,导致负数原有符号位失效变成一个大数进行比较,例如:
(int8)-1 > (uint32)0,这里的(int8)-1也就当成(uint32)255进行比较。 - 无符号有符号数互相强制转换。和上面的问题一样,无符号数最高位为1的时候会转成负数,负数的有符号数也会强制转成负数原有符号位失效的无符号大数。
- 左移右移运算符。使用位移运算符时,CPU会自动将符号提升,也就是uint8会转成uint32(针对于32位CPU来说),也就是大多数和CPU位数对齐,所以也就可能会出现类似这种情况:正常来说int8的0x80赋值给int32为-128,但是如果是
uint32 a = ((int8)0x40 << 1),就会得到a为正数的128。 - 这个问题不只是举例的这几种,有可能是其它的组合情况,但是如果把这些举例想明白了,别的情况也就一通百通了。
2.6. CPU占用100%(常见程度⭐⭐)
- 任务处理不过来(例如:间隔40毫秒的采样任务使用冒泡排序处理长数组),通常这种情况都是在运行频率比较高的任务中改代码才会出现,运行频率不高的任务加再多的循环代码通常也不会出现长期占用CPU百分百的情况。(常见程度⭐)
- 死循环,通常CPU占用100%大概率都是出现死循环,也不一定是直接的一个死循环,而是间接导致某个值越界、溢出导致的死循环,例如:将上面的数值越界问题的条件放到循环条件中。(常见程度⭐⭐⭐⭐⭐)
- 间接导致出现意料外的长任务,例如:存的日志没有加长度限制,然后调用了日志输出的功能,也就一直占满CPU来打印日志。通常这种问题比较隐蔽,都是一些没考虑好的情况。(常见程度⭐⭐⭐⭐)
2.7. 网络相关问题**(常见程度⭐⭐⭐)**
- 如果是连接莫名其妙断开的问题,可以查看日志的网络故障信息(如连接退出位置、错误码、重连原因等),可帮助定位问题。
- 如果是长时间连不上网,那么就抓包看一下二层发的什么数据,或者查看是否出现CPU百分百的情况,如果CPU百分百那么也就是高优先级的任务一直占用导致DHCP任务得不到运行,导致分配不到IP也就连不上网。
- 如果是socket分配失败问题,可能是NDK静态内存不足或者是堆内存不足,通常这种情况就要检查是不是有socket使用完没有close,是不是有malloc使用完没有free(通常应尽量避免频繁使用动态内存分配,容易造成内存碎片)。
- 查看errno值,也就能确定大概问题是啥原因,例如:超时、路由未找到、连接被重置等,在errno里都能找到。
- 复杂问题就需要看抓包,看wireshark中的错误提示,例如:出现arp广播包找不到本机、出现包被分组也就是某个字段长度设置错了、对方强制关闭连接等。抓包可以在本机模拟消息来抓包、路由器抓包、服务器抓包,看需求再选择在哪抓包,通常大部分问题都是在路由器中抓包。
- 通过网络调试助手(如 netassist.exe)工具手动拼接数据模拟发送报文。
2.8. 看门狗重启**(常见程度⭐⭐)**
2.8.1. 看门狗类型
看门狗分为内部看门狗和外部看门狗,为方便调试外部看门狗只有在接入跳线帽后才会启用。
2.8.2. 喂狗机制
喂狗的代码通常只在一个任务(例如 FeedDogTask)中定时喂狗。
2.8.3. 常见的导致看门狗重启的情况
- 某个地方关中断没有再打开。****(常见程度⭐⭐⭐⭐)
- 某个高优先级的任务一直占用CPU不释放。****(常见程度⭐⭐⭐)
- 中断服务函数执行时间过长。****(常见程度⭐⭐⭐)
- 任务崩溃或者系统崩溃。****(常见程度⭐⭐)
2.8.4. 常用的排查方法
- 降低高优先级任务的优先级。
- 在开关中断的源码中添加记录时长的代码。
- 记录中断服务函数单次执行时长。
2.9. 芯片问题**(常见程度⭐)**
- 查阅芯片勘误表,例如:TM4C123重启有概率总线异常、时钟不准(之前出现过)。
- 论坛中搜索关键词,例如:出现问题的现象,出现问题的函数名等。
2.10. 疑似硬件问题**(常见程度⭐)**
- 让硬件工程师来检查。
3. 调试经验
3.1. 程序下载校验
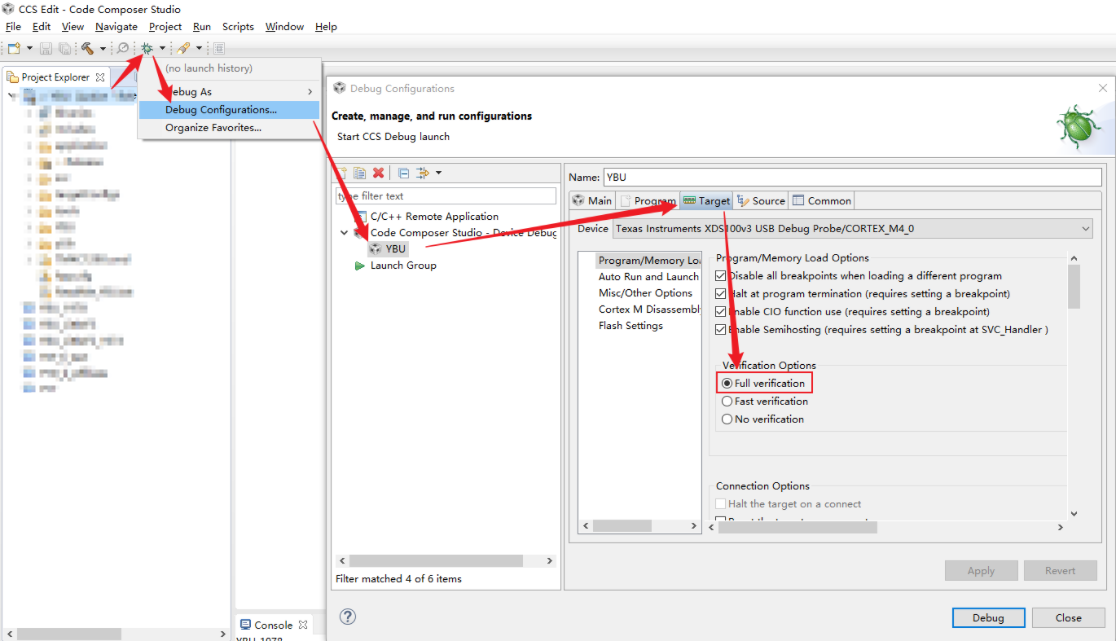
下载的程序一定要用全校验,否则会部分指令有概率错乱,也就有概率崩溃,通常表现为单步走到汇编伪指令不识别的指令。以CCS为例,设置全校验的方法:在调试配置的 Flash Settings 中选择 "Full Verification"。
3.2. 排查问题基本流程(需要灵活变化)
graph TD;
开始 --> 问题复现 --> 备份程序 --> 备份配置 --> 本地尝试复现 --> 是否能确定出现问题的代码范围{是否能确定出现问题的代码范围};
是否能确定出现问题的代码范围 -- 是 --> 确定代码范围是否为百分百复现问题{是否为百分百复现问题};
是否能确定出现问题的代码范围 -- 否 --> 不确定代码范围是否为百分百复现问题{是否为百分百复现问题};
确定代码范围是否为百分百复现问题 -- 是 --> 直接单步调试 --> 结束;
确定代码范围是否为百分百复现问题 -- 否 --> 等问题复现["添加测试代码、测试变量、记录日志<br>通过脚本监听,等问题复现"] --> 问题复现
不确定代码范围是否为百分百复现问题-- 是 --> 二分法确定问题代码范围["二分法(记录日志、变量赋值等方式)确定问题代码范围"] --> 确定代码范围是否为百分百复现问题;
不确定代码范围是否为百分百复现问题-- 否 --> 寻找复现规律["寻找复现规律:<br>使用现场配置<br>接入现场相同设备<br>尝试复现时候的相同操作<br>远程查看现场内存值等"] --> 问题复现;
3.3. 想办法复现问题
- 保存配置,使用现场配置;
- 接入现场相同设备;
- 模拟当时相同操作(例如:收到哪些MQTT消息、modbus指令、屏幕操作等)。
3.4. 二分法确定问题位置
- 大方向通过修改配置、注释任务来确定哪个任务;
- 任务内通过打印日志、赋值全局变量来确定是哪个函数;
- 函数内就可以直接通过单步调试来确定具体是哪一行。
3.5. 剖析源码法
在调用别人的代码时候出现的问题,只能看源码来排查,而不是猜里面会怎样实现,找到根本原因后写代码也能放心,例如:静态任务用不了Socket的问题、Socket有概率分配失败的问题、频繁重启有概率总线异常的问题等。
3.5.1. 单步调试进入源码法
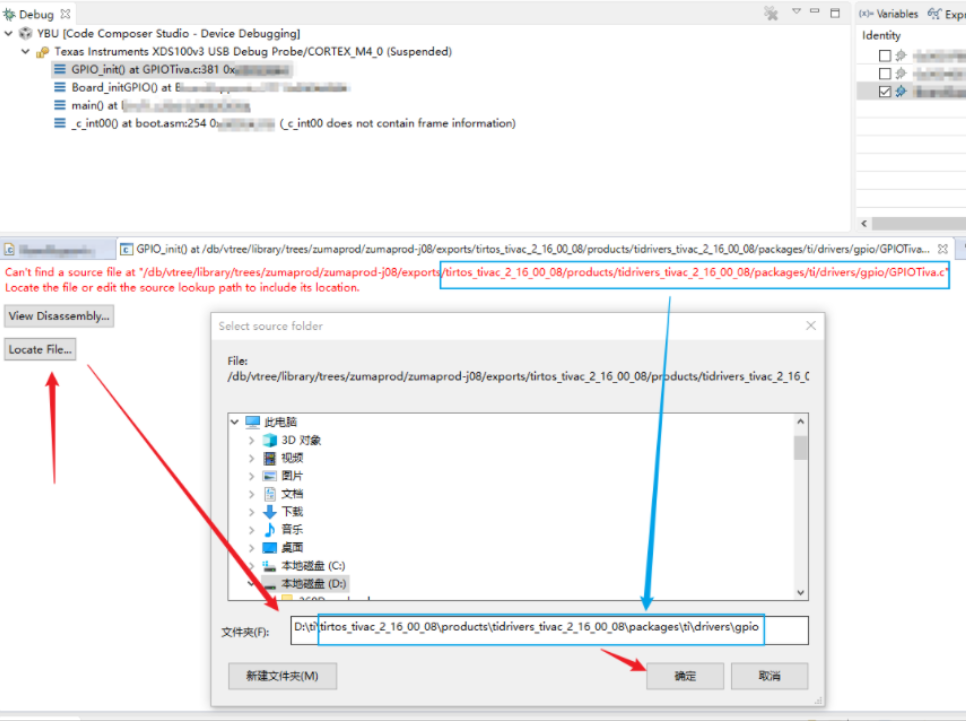
在需要看源码函数调用的地方下断点,单步进入函数里面,也就能看到源码,如果提示找不到文件时候需要自己选择文件路径,通常在IDE安装目录下就能找到,如果实在是找不到的话用everything工具就能找到需要的文件。选择文件方法:
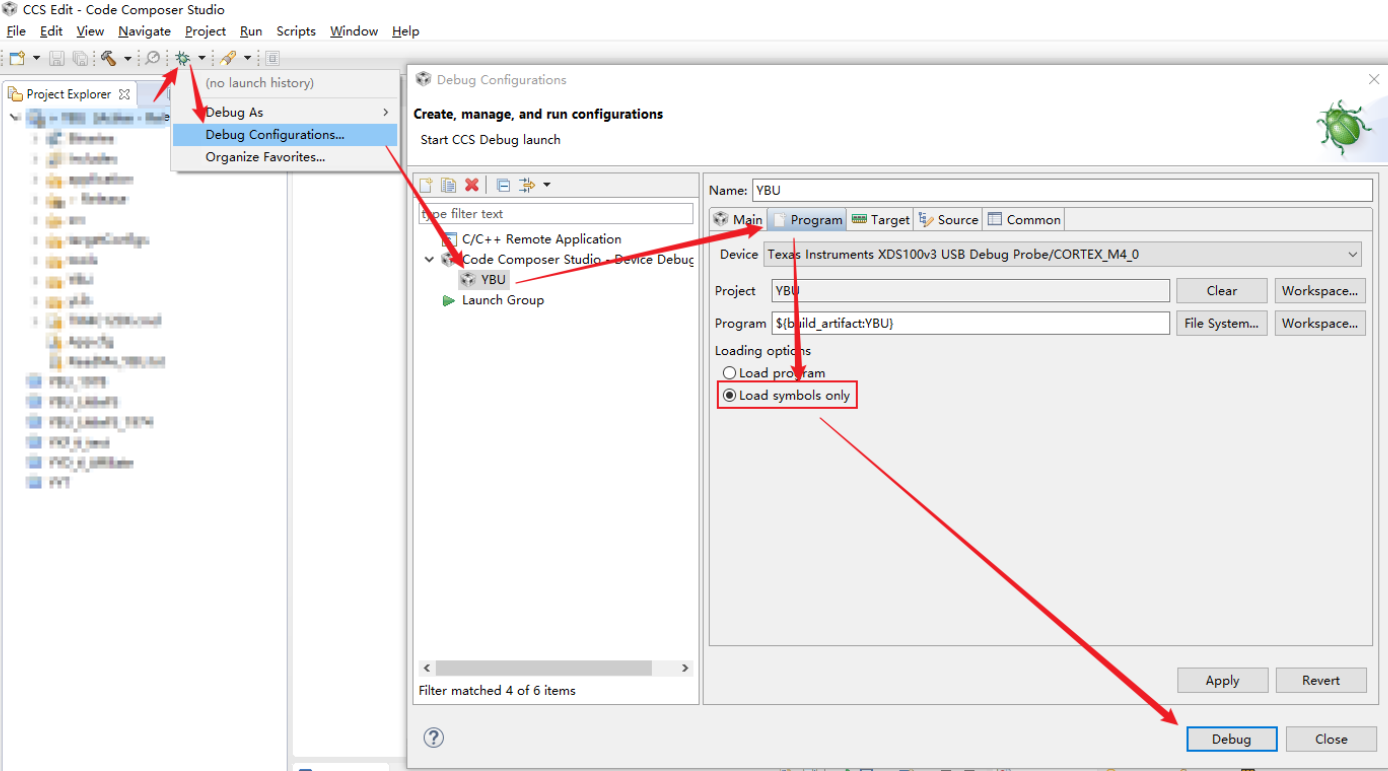
3.5.2. 源码复制到项目
如果出问题的代码不多的情况,或者需要在源码中下断点的情况,可以将源码复制到项目目录下。如果出现include错误,也需要将引用的其它文件复制过来。
3.6. 不合理即是bug
例如:消息特别多的时候会导致MQTT重连,如果只是调整了消息数量而不研究为什么重连,这种问题以后在现场可能还会复现,并且不好处理。好不容易复现出来问题就不要遗漏掉,记下来现场判断原因,最后很有可能发现个大bug,或者是设计上的缺陷。
4. 调试工具
4.1. 提供一个远程内存打印后门
通过预留加密的MQTT接口和脚本,实现一套能够远程打印现场板子的内存、EEPROM、Flash内容的调试工具。通常根据map文件查看需要的变量地址,再通过这个脚本就能得到变量值,方便确定现场问题。
4.2. 调试器重连方法
板子复现了问题、电脑重启等情况,需要重新连接调试器,可以在IDE中通过 "Reconnect JTAG" 功能实现。
4.3. 临时全局调试变量
可在程序中预先定义一个或多个用于临时调试的全局变量(例如一个结构体数组),即使在生产环境中也可保留。其主要目的是在发现问题后,需要添加调试代码时,能在尽量不改变内存编址的情况下记录调试值。
4.4. 崩溃现场
可在程序中对Raise、Abort、HardFault、Exit等异常设置钩子函数,出现这些异常情况时自动打印并存储“崩溃现场”信息,并可通过网络上报(如MQTT)。
建议记录的崩溃现场信息应包含:
- pc 寄存器:下一条将要执行指令的地址,崩溃发生地址通常为其上一条指令地址。
- lr 寄存器:程序跳转返回地址,用于定位非法函数指针的调用点。
- 通用寄存器(r0~r12):函数调用参数,可推断崩溃时的函数入参。
- 异常消息:如系统或自定义的 Raise 消息内容。
- 栈帧内容:用于手动回溯函数调用链。
- 崩溃任务栈地址:用于定位崩溃发生的任务。
4.5. 设备诊断信息上报
建议实现一个设备诊断信息上报机制(例如在设备入网时主动上报一次),以便远程感知设备状态和排查故障。上报信息应尽可能包含以下的关键数据:
- 重启原因与重启次数:用于判断设备是否频繁复位及复位来源(如看门狗、掉电、软件异常等)。
- 网络连接情况:应记录连接退出位置、最后一次失败错误码、连接尝试次数、重连原因及重连前错误码、网络建立连接耗时等,便于排查网络不稳定或断连问题。
- 设备基础信息:软件版本号、编译时间、设备唯一标识(如序列号、MAC地址)、IP 地址、时间同步状态等。
- 运行状态标记:如关键应用模块的使能状态,可用于快速判断配置问题。
以上信息可格式化为 JSON 等结构通过网络定时或事件触发上报,当设备频繁上报诊断信息时,往往暗示设备存在频繁复位或反复断网重连的异常行为。
4.6. 现场故障监听
可建立一个主动发现问题的监听渠道,通过程序自动识别一些疑似问题的情况,设置触发条件和通知邮箱,出现问题主动发送通知,减少对人工反馈的依赖。
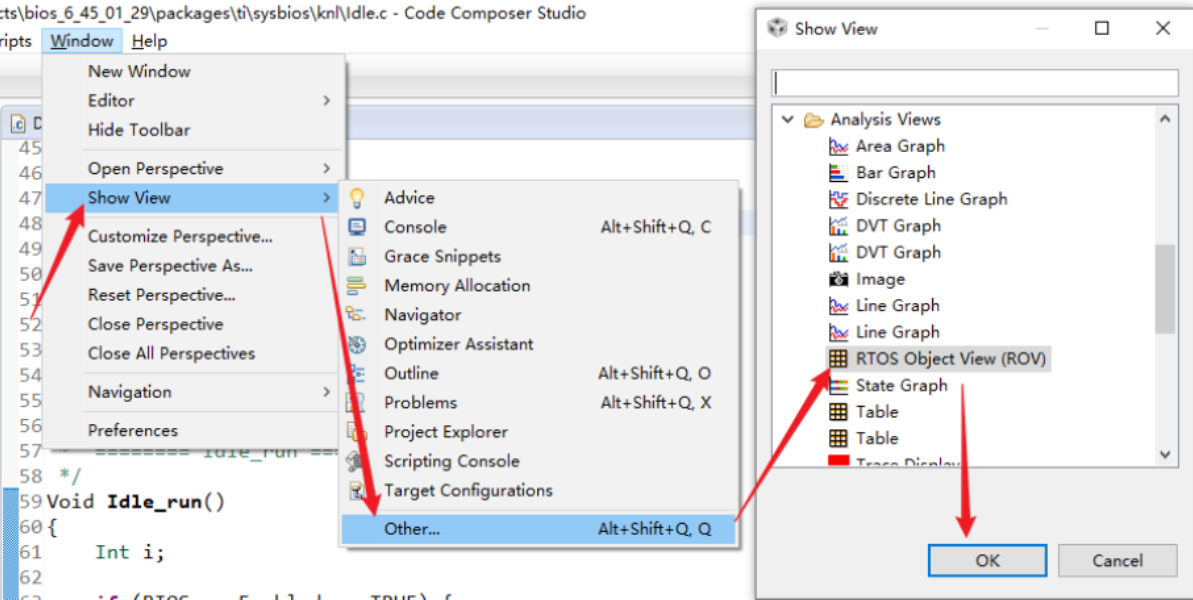
4.7. ROV(Runtime Object View)
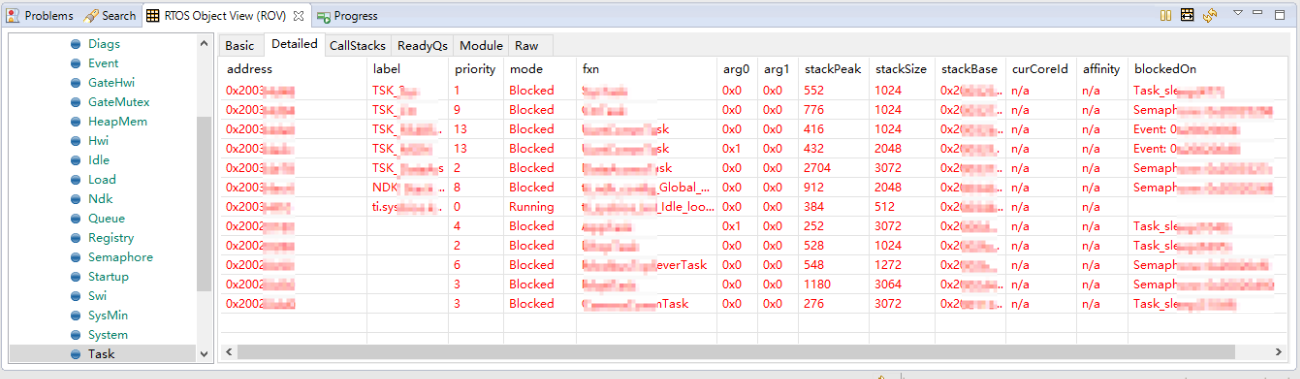
RTOS通常提供运行时对象查看工具(如 TI-RTOS 的 ROV),主要用来看每个任务的栈是否溢出,每个任务运行到哪个代码了,回溯每个任务的栈等。当然除了任务也能看其它系统相关的监听数据,例如:中断、信号量、定时器等,但最常用还是看任务的状态和回溯任务栈。
注意:某些 IDE 版本可能存在 bug,打开 ROV 调试时可能会卡顿,重启 IDE 通常可解决。
打开 ROV 的方法一般位于调试视图的 Tools 菜单中。
Task 视图(常用部分):
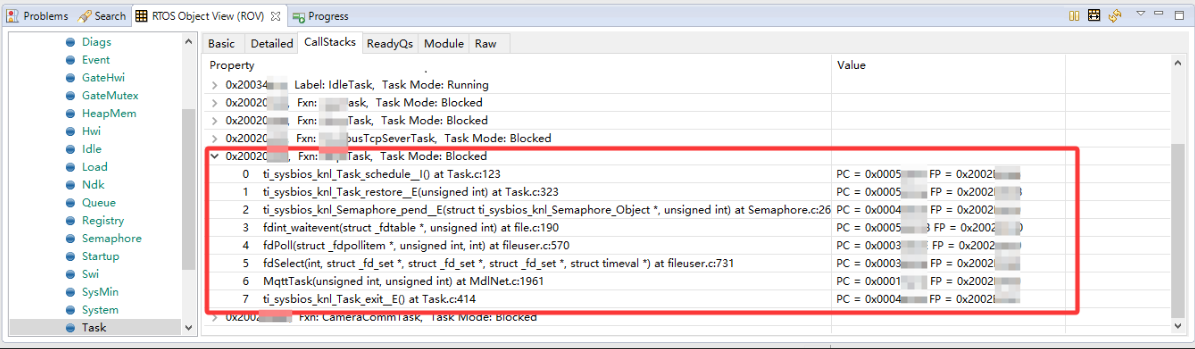
4.8. 内存预览
IDE调试器中通常提供内存浏览器(Memory Browser),可直接查看指定地址的内存数据。
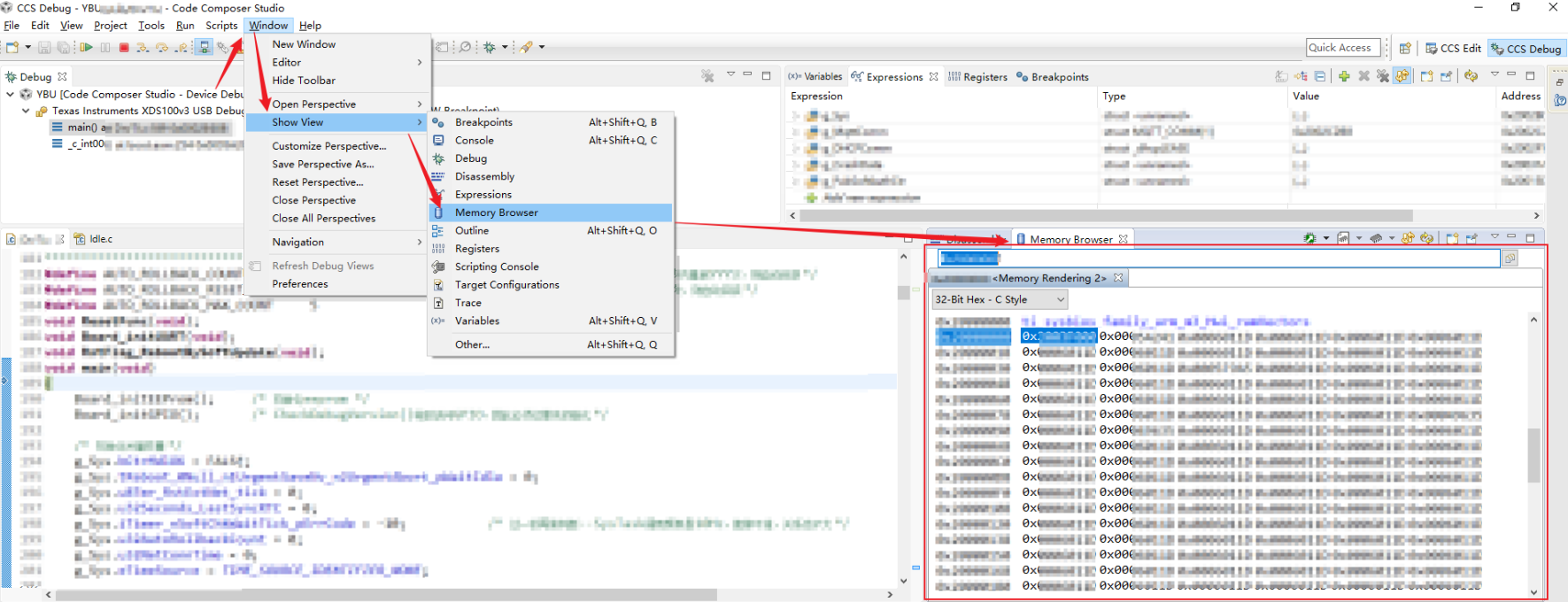
4.9. 内存反编译预览
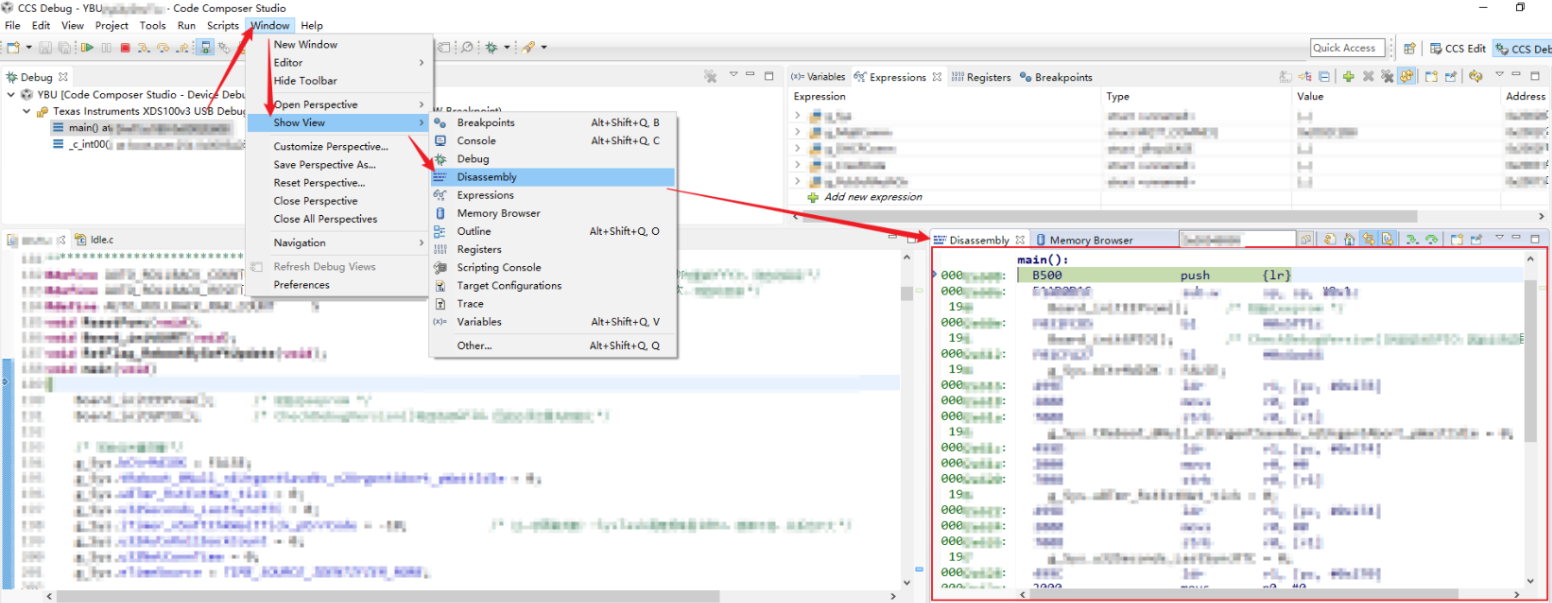
IDE调试器中通常提供反汇编视图(Disassembly),可查看内存地址对应的汇编指令。
4.10. 调用栈
IDE调试器在程序暂停时可显示当前函数调用栈(Call Stack),方便回溯函数调用关系。